Logos Handbook

![]()


Hi there!
Logos is a fast and easy to use lexer generator written in Rust. While Rust has excellent documentation tools (and you can access the API docs for Logos at docs.rs), it’s not the easiest thing to document custom syntax used by procedural macros, of which Logos has a bit. This Handbook seeks to remedy this!
In a nutshell
There are two main types in Logos:
- The
Logostrait, which comes out with its own derive macro. The derive macro uses custom attributes (the things using these brackets:#[...]) with plain string or regular expression syntax onenumvariants as patterns for some input. - The
Lexer<T: Logos>, which is an iterator that takes some input (&str, sometimes&[u8]) and performs lexical analysis on the input on the go, producing variants of the enumTmatching the defined patterns.
Getting Started
Logos can be included in your Rust project using the cargo add logos command, or by directly modifying your Cargo.toml file:
[dependencies]
logos = "0.16.1"
Then, you can automatically derive the Logos trait on your enum using the Logos derive macro:
#![allow(unused)]
fn main() {
use logos::Logos;
#[derive(Logos, Debug, PartialEq)]
#[logos(skip r"[ \t\n\f]+")] // Ignore this regex pattern between tokens
enum Token {
// Tokens can be literal strings, of any length.
#[token("fast")]
Fast,
#[token(".")]
Period,
// Or regular expressions.
#[regex("[a-zA-Z]+")]
Text,
}
}Then, you can use Logos::lexer method to turn any &str into an iterator of tokens1:
#![allow(unused)]
fn main() {
let mut lex = Token::lexer("Create ridiculously fast Lexers.");
assert_eq!(lex.next(), Some(Ok(Token::Text)));
assert_eq!(lex.span(), 0..6);
assert_eq!(lex.slice(), "Create");
assert_eq!(lex.next(), Some(Ok(Token::Text)));
assert_eq!(lex.span(), 7..19);
assert_eq!(lex.slice(), "ridiculously");
assert_eq!(lex.next(), Some(Ok(Token::Fast)));
assert_eq!(lex.span(), 20..24);
assert_eq!(lex.slice(), "fast");
assert_eq!(lex.next(), Some(Ok(Token::Text)));
assert_eq!(lex.slice(), "Lexers");
assert_eq!(lex.span(), 25..31);
assert_eq!(lex.next(), Some(Ok(Token::Period)));
assert_eq!(lex.span(), 31..32);
assert_eq!(lex.slice(), ".");
assert_eq!(lex.next(), None);
}Because Lexer, returned by Logos::lexer, implements the Iterator trait, you can use a for .. in construct:
#![allow(unused)]
fn main() {
for result in Token::lexer("Create ridiculously fast Lexers.") {
match result {
Ok(token) => println!("{:#?}", token),
Err(e) => panic!("some error occurred: {}", e),
}
}
}-
Each item is actually a
Result<Token, _>, because the lexer returns an error if some part of the string slice does not match any variant ofToken. ↩
Getting Help
If you need help using Logos, there are three places you can go to depending on what you are looking for:
- this book for a documented walk through Logos’ usage, with detailed examples, and more. A must read for any newcomer;
- the API documentation to obtain precise information about function signatures and what the Logos crate exposes in terms of features;
- and GitHub issues for anything else that is not covered by any of the two above.
Regarding GitHub issues, it’s highly recommended to first check if another issue, either open or closed, already covers the topic you are looking for. If not, then consider creating a new issue with necessary information about your question, problem or else.
Attributes
The #[derive(Logos)] procedural macro recognizes three different attribute
names.
#[logos]is the main attribute which can be attached to theenumof your token definition. It allows you to define theExtrasassociated type in order to put custom state into theLexer, or declare concrete types for generic type parameters, if yourenumuses such. It is strictly optional. It also allows to define parts that must be skipped by the lexer, the error type, or regex subpatterns.- And most importantly the
#[token]and#[regex]attributes. Those allow you to define patterns to match against the input, either plain text strings with#[token], or using regular expression syntax with#[regex]. Aside from that difference, they are equivalent, and any extra arguments you can pass to one, you can pass to the other.
#[logos]
As previously said, the #[logos] attribute can be attached to the enum
of your token definition to customize your lexer. Note that they all are
optional.
The syntax is as follows:
#![allow(unused)]
fn main() {
#[derive(Logos)]
#[logos(skip "regex literal")]
#[logos(skip("regex literal"[, callback, priority = <integer>]))]
#[logos(extras = ExtrasType)]
#[logos(error = ErrorType)]
#[logos(crate = path::to::logos)]
#[logos(utf8 = true)]
#[logos(lifetime = 's)]
#[logos(subpattern subpattern_name = "regex literal")]
enum Token {
/* ... */
}
}where "regex literal" can be any regex supported by
#[regex], and ExtrasType can be of any type!
An example usage of skip is provided in the JSON parser example.
For more details about extras, read the eponym section.
Custom error type
By default, Logos uses () as the error type, which means that it
doesn’t store any information about the error.
This can be changed by using #[logos(error = ErrorType)] attribute on the enum.
The type ErrorType can be any type that implements Clone, PartialEq,
Default and From<E> for each callback’s error type.
Here is an example using a custom error type:
use logos::Logos;
use std::num::ParseIntError;
#[derive(Default, Debug, Clone, PartialEq)]
enum LexingError {
InvalidInteger(String),
NonAsciiCharacter(char),
#[default]
Other,
}
/// Error type returned by calling `lex.slice().parse()` to u8.
impl From<ParseIntError> for LexingError {
fn from(err: ParseIntError) -> Self {
use std::num::IntErrorKind::*;
match err.kind() {
PosOverflow | NegOverflow => LexingError::InvalidInteger("overflow error".to_owned()),
_ => LexingError::InvalidInteger("other error".to_owned()),
}
}
}
impl LexingError {
fn from_lexer(lex: &mut logos::Lexer<'_, Token>) -> Self {
LexingError::NonAsciiCharacter(lex.slice().chars().next().unwrap())
}
}
#[derive(Debug, Logos, PartialEq)]
#[logos(error(LexingError, LexingError::from_lexer))]
#[logos(skip r"[ \t]+")]
enum Token {
#[regex(r"[a-zA-Z]+")]
Word,
#[regex(r"[0-9]+", |lex| lex.slice().parse())]
Integer(u8),
}
fn main() {
// 256 overflows u8, since u8's max value is 255.
// 'é' is not a valid ASCII letter.
let mut lex = Token::lexer("Hello 256 Jérome");
assert_eq!(lex.next(), Some(Ok(Token::Word)));
assert_eq!(lex.slice(), "Hello");
assert_eq!(
lex.next(),
Some(Err(LexingError::InvalidInteger(
"overflow error".to_owned()
)))
);
assert_eq!(lex.slice(), "256");
assert_eq!(lex.next(), Some(Ok(Token::Word)));
assert_eq!(lex.slice(), "J");
assert_eq!(lex.next(), Some(Err(LexingError::NonAsciiCharacter('é'))));
assert_eq!(lex.slice(), "é");
assert_eq!(lex.next(), Some(Ok(Token::Word)));
assert_eq!(lex.slice(), "rome");
assert_eq!(lex.next(), None);
}You can add error variants to LexingError,
and implement From<E> for each error type E that could
be returned by a callback. See callbacks.
ErrorType must implement the Default trait because invalid tokens, i.e.,
literals that do not match any variant, will produce Err(ErrorType::default()).
Alternatively, you can provide a callback with the alternate syntax
#[logos(error(ErrorType, callback = ...))], which allows you to include information
from the lexer such as the span where the error occurred:
#[derive(Logos)]
#[logos(error(Range<usize>, callback = |lex| lex.span()))]
enum Token {
#[token("a")]
A,
#[token("b")]
B,
}Specifying path to logos
You can force the derive macro to use a different path to Logos’ crate
with #[logos(crate = path::to::logos)].
Custom source type
By default, Logos’ lexer will accept &str as input. If any of the tokens
or regex patterns can match a non UTF-8 bytes sequence, this will cause a
compile-time error. In this case, you should supply #[logos(utf8 = false)].
This will cause the lexer to accept a &[u8] instead.
In the past, you could also specify any custom type, but that feature has been removed.
Explicit source lifetime
When the source lifetime is left unspecified, Logos will use the lifetime of the
token type as the source (in enum Token<'a>, 'a will become the source lifetime).
The token lifetime is set to 's in the extras type, in concrete type declarations and
in callbacks when using an implicit source lifetime. When no lifetime is present on the
token type, a new 's lifetime is generated as the source.
You can specify the source lifetime explicitly using #[logos(lifetime = 'a)] to use
lifetime 'a from the token lifetime parameters, or use #[logos(lifetime = none)] to
add a new source lifetime 's instead. Token lifetimes are not set to 's when using
an explicit source lifetime. If your token type has multiple lifetimes, the source
lifetime must be set explicitly.
Here is a small example using an explicit source lifetime:
#[derive(Logos)]
#[logos(lifetime = 's)]
enum Foo<'s, 'a> {
#[token("bar", |lex| lex.slice())]
Bar(&'s str),
#[token("baz", |_| "static")]
Baz(&'a str),
}For a more complete example, see the array language example.
Subpatterns
We can use subpatterns to reuse regular expressions in our tokens or other subpatterns.
The syntax to use a previously defined subpattern, like #[logos(subpattern subpattern_name = "regex literal")],
in a new regular expression is "(?&subpattern_name)".
For example:
use logos::Logos;
#[derive(Logos, Debug, PartialEq)]
#[logos(skip r"\s+")]
#[logos(subpattern alpha = r"[a-zA-Z]")]
#[logos(subpattern digit = r"[0-9]")]
#[logos(subpattern alphanum = r"(?&alpha)|(?&digit)")]
enum Token {
#[regex("(?&alpha)+")]
Word,
#[regex("(?&digit)+")]
Number,
#[regex("(?&alphanum){2}")]
TwoAlphanum,
#[regex("(?&alphanum){3}")]
ThreeAlphanum,
}
fn main() {
let mut lex = Token::lexer("Word 1234 ab3 12");
assert_eq!(lex.next(), Some(Ok(Token::Word)));
assert_eq!(lex.slice(), "Word");
assert_eq!(lex.next(), Some(Ok(Token::Number)));
assert_eq!(lex.slice(), "1234");
assert_eq!(lex.next(), Some(Ok(Token::ThreeAlphanum)));
assert_eq!(lex.slice(), "ab3");
assert_eq!(lex.next(), Some(Ok(Token::TwoAlphanum)));
assert_eq!(lex.slice(), "12");
assert_eq!(lex.next(), None);
}(Note that the above subpatterns are redundant as the same can be achieved with existing character classes)
#[token] and #[regex]
For each variant you declare in your enum that uses the Logos derive macro,
you can specify one or more string literal or regex it can match.
The usage syntax is as follows:
#![allow(unused)]
fn main() {
#[derive(Logos)]
enum Token {
#[token(literal [, callback, priority = <integer>, ignore(<flag>, ...)]]
#[regex(literal [, callback, priority = <integer>, ignore(<flag>, ...)]]
SomeVariant,
}
}where literal can be any &str or &[u8] string literal,
callback can either be a closure, or a literal path to a function
(see Using callbacks section),
priority can be any positive integer
(see Token disambiguation section),
and the only flag value is: case. Only literal is required,
others are optional.
You can stack any number of #[token] and or #[regex] attributes on top of
the same variant.
Note
For a list of supported
regexliterals, read the Common regular expressions section.
Token disambiguation
When two or more tokens can match a given sequence, Logos compute the
priority of each pattern (#[token] or #[regex]), and use that priority
to decide which pattern should match.
The rule of thumb is:
- Longer beats shorter.
- Specific beats generic.
If any two definitions could match the same input, like fast and [a-zA-Z]+
in the example above, it’s the longer and more specific definition of Token::Fast
that will be the result.
This is done by comparing numeric priority attached to each definition. Every consecutive, non-repeating single byte adds 2 to the priority, while every range or regex class adds 1. Loops or optional blocks are ignored, while alternations count the shortest alternative:
[a-zA-Z]+has a priority of 2 (lowest possible), because at minimum it can match a single byte to a class;foobarhas a priority of 12;- and
(foo|hello)(bar)?has a priority of 6,foobeing its shortest possible match.
Generally speaking, equivalent regex patterns have the same priority. E.g.,
a|b is equivalent to [a-b], and both have a priority of 2.
Note
When two different patterns have the same priority, Logos will issue a compilation error. To prevent this from happening, you can manually set the priority of a given pattern with, e.g.,
#[token("foobar", priority = 20)].
Using Extras
When deriving the Logos traits, you may want to convey some internal state
between your tokens. That is where Logos::Extras comes to the rescue.
Each Lexer has a public field called extras that can be accessed and
mutated to keep track and modify some internal state. By default,
this field is set to (), but its type can by modified using the derive
attribute #[logos(extras = <some type>)] on your enum declaration.
For example, one may want to know the location, both line and column indices, of each token. This is especially useful when one needs to report an erroneous token to the user, in a user-friendly manner.
/// Simple tokens to retrieve words and their location.
#[derive(Debug, Logos)]
#[logos(extras = (usize, usize))]
#[logos(skip(r"\n", newline_callback))]
enum Token {
#[regex(r"\w+", word_callback)]
Word((usize, usize)),
}The above token definition will hold two tokens: Newline and Word.
The former is only used to keep track of the line numbering and will be skipped
using Skip as a return value from its callback function. The latter will be
a word with (line, column) indices.
To make it easy, the lexer will contain the following two extras:
extras.0: the line number;extras.1: the char index of the current line.
We now have to define the two callback functions:
/// Update the line count and the char index.
fn newline_callback(lex: &mut Lexer<Token>) -> Skip {
lex.extras.0 += 1;
lex.extras.1 = lex.span().end;
Skip
}
/// Compute the line and column position for the current word.
fn word_callback(lex: &mut Lexer<Token>) -> (usize, usize) {
let line = lex.extras.0;
let column = lex.span().start - lex.extras.1;
(line, column)
}Extras can of course be used for more complicate logic, and there is no limit
to what you can store within the public extras field.
Finally, we provide you the full code that you should be able to run with[^1]:
cargo run --example extras Cargo.toml
[^1] You first need to clone this repository.
use logos::{Lexer, Logos, Skip};
use std::env;
use std::fs;
/// Update the line count and the char index.
fn newline_callback(lex: &mut Lexer<Token>) -> Skip {
lex.extras.0 += 1;
lex.extras.1 = lex.span().end;
Skip
}
/// Compute the line and column position for the current word.
fn word_callback(lex: &mut Lexer<Token>) -> (usize, usize) {
let line = lex.extras.0;
let column = lex.span().start - lex.extras.1;
(line, column)
}
/// Simple tokens to retrieve words and their location.
#[derive(Debug, Logos)]
#[logos(extras = (usize, usize))]
#[logos(skip(r"\n", newline_callback))]
enum Token {
#[regex(r"\w+", word_callback)]
Word((usize, usize)),
}
fn main() {
let src = fs::read_to_string(env::args().nth(1).expect("Expected file argument"))
.expect("Failed to read file");
let mut lex = Token::lexer(src.as_str());
while let Some(token) = lex.next() {
if let Ok(Token::Word((line, column))) = token {
println!("Word '{}' found at ({}, {})", lex.slice(), line, column);
}
}
}Using callbacks
Logos can also call arbitrary functions whenever a pattern is matched, which can be used to put data into a variant:
use logos::{Logos, Lexer};
// Note: callbacks can return `Option` or `Result`
fn kilo(lex: &mut Lexer<Token>) -> Option<u64> {
let slice = lex.slice();
let n: u64 = slice[..slice.len() - 1].parse().ok()?; // skip 'k'
Some(n * 1_000)
}
fn mega(lex: &mut Lexer<Token>) -> Option<u64> {
let slice = lex.slice();
let n: u64 = slice[..slice.len() - 1].parse().ok()?; // skip 'm'
Some(n * 1_000_000)
}
#[derive(Logos, Debug, PartialEq)]
#[logos(skip r"[ \t\n\f]+")]
enum Token {
// Callbacks can use closure syntax, or refer
// to a function defined elsewhere.
//
// Each pattern can have its own callback.
#[regex("[0-9]+", |lex| lex.slice().parse().ok())]
#[regex("[0-9]+k", kilo)]
#[regex("[0-9]+m", mega)]
Number(u64),
}
fn main() {
let mut lex = Token::lexer("5 42k 75m");
assert_eq!(lex.next(), Some(Ok(Token::Number(5))));
assert_eq!(lex.slice(), "5");
assert_eq!(lex.next(), Some(Ok(Token::Number(42_000))));
assert_eq!(lex.slice(), "42k");
assert_eq!(lex.next(), Some(Ok(Token::Number(75_000_000))));
assert_eq!(lex.slice(), "75m");
assert_eq!(lex.next(), None);
}Logos can handle callbacks with following return types:
| Return type | Produces |
|---|---|
() | Ok(Token::Unit) |
bool | Ok(Token::Unit) or Err(<<Token as Logos>::Error as Default>::default()) |
Result<(), E> | Ok(Token::Unit) or Err(<Token as Logos>::Error::from(err)) |
T | Ok(Token::Value(T)) |
Option<T> | Ok(Token::Value(T)) or Err(<<Token as Logos>::Error as Default>::default()) |
Result<T, E> | Ok(Token::Value(T)) or Err(<Token as Logos>::Error::from(err)) |
Skip | skips matched input |
Result<Skip, E> | skips matched input or Err(<Token as Logos>::Error::from(err)) |
Filter<T> | Ok(Token::Value(T)) or skips matched input |
FilterResult<T, E> | Ok(Token::Value(T)) or Err(<Token as Logos>::Error::from(err)) or skips matched input |
Callbacks can also be used to perform more specialized lexing in places
where regular expressions are too limiting. For specifics look at
Lexer::remainder and
Lexer::bump.
Callbacks can also be used with #[logos(skip)], in which case the callback should return Skip or ().
Context-dependent lexing
Sometimes, a single lexer is insufficient to properly handle complex grammars. To address this, many lexer generators offer the ability to have separate lexers with their own set of patterns and tokens, allowing you to dynamically switch between them based on the context.
In Logos, context switching is handled using the morph method of the logos::Lexer struct.
This method takes ownership of the current lexer and transforms it into a lexer for a new token type.
It is important to note that:
- Both the original lexer and the new lexer must share the same
Sourcetype. - The
Extrastype from the original lexer must be convertible into theExtrastype of the new lexer.
Example
The following example demonstrates how to use morph to handle a C-style language that also supports Python blocks:
#![allow(unused)]
fn main() {
#[derive(Logos, Debug, PartialEq, Clone)]
#[logos(skip r"\s+")]
enum CToken {
/* Tokens supporting C syntax */
// ...
#[regex(r#"extern\s+"python"\s*\{"#, python_block_callback)]
PythonBlock(Vec<PythonToken>),
}
#[derive(Logos, Debug, PartialEq, Clone)]
#[logos(skip r"\s+")]
enum PythonToken {
#[token("}")]
ExitPythonBlock,
/* Tokens supporting Python syntax */
// ...
}
fn python_block_callback(lex: &mut Lexer<CToken>) -> Option<Vec<PythonToken>> {
let mut python_lexer = lex.clone().morph::<PythonToken>();
let mut tokens = Vec::new();
while let Some(token) = python_lexer.next() {
match token {
Ok(PythonToken::ExitPythonBlock) => break,
Err(_) => return None,
Ok(tok) => tokens.push(tok),
}
}
*lex = python_lexer.morph();
Some(tokens)
}
}Note that if we want to use morph inside a callback we need to be able to clone the original lexer, as morph needs to take ownership but the callback receives only a reference to the lexer.
For a more in depth example check out String interpolation.
Regular expressions
Maybe the most important feature of Logos is its ability to accept regex patterns in your tokens’ definition.
Regular expressions,
or regexes for short, are sequences of characters (or bytes) that define a match
pattern. When constructing lexers, this is especially useful to define tokens
that should match a set of similar literals. E.g., a sequence of
3 ASCII uppercase letters and 3 digits could define a license plate,
and could be matched with the following regex: "[A-Z]{3}[0-9]{3}".
For more details about regexes in Rust, refer to the regex crate.
Regex Flags
Regular expression flags are a useful way to change the behavior of regular
expressions. For example, enabling them flag (stands for “multiline”) causes
the dot . to match newlines. The i flag causes the pattern to ignore case.
To enable a flag, either toggle it on with (?<flag>), or enable it using a
flag group, like so (?<flag>:<pattern>). For example
r"(?m).*"will match the entire input. Without themflag, it would only match the entire first line.r"(?i:c)afe"will match both"cafe"and"Cafe"
For more information about regex flags, see the regex crate
documentation.
Common performance pitfalls
Because Logos aims at generating high-performance code, its matching engine
will never backtrack during a token. However, it is possible that it will have
to re-read bytes that it already read while lexing the previous token. As an
example, consider the regex "a(.*b)?". When trying to parse tokens on a file
full of a characters, the engine must read the entire file to see if there is
a b character anywhere. Properly tokenizing this pattern creates a surprising
performance of O(n^2) where n is the size of the file. Indeed, any pattern
that contains an unbounded greedy dot repetition requires reading the entire
file before returning the next token. Since this is almost never the intended
behavior, logos returns a compile-time error by default when encountering
patterns containing .* and .+. If this is truly your intention, you can add
the flag allow_greedy = true to your #[regex] attribute. But first
consider whether you can instead use a non-greedy repetition, which would also
resolve the performance concern.
For reference, Logos parses regexes using the regex-syntax and
regex-automata crates, and transforms the deterministic finite automata
created by the regex-automata crate into Rust code that implements the
matching state machine. Every regex is compiled with an implicit ^ anchor at
its start, since that is how a tokenizer works.
Additionally, note that capture groups will be silently changed to non
capturing, because Logos does not support capturing groups, only the whole
match group returned by lex.slice().
If any of these limitations are problematic, you can move more of your matching
logic into a callback, possibly using the
Lexer::bump
function.
Error semantics
The matching semantics for returning an error are as follows. An error is
generated when the lexer encounters a byte that doesn’t have an transition for
its current state. This means that this adding this byte to the currently read
byte string makes it impossible to match any defined #[regex] or
#[token]. An error token is then returned with a span up to but not
including the byte that caused the error, unless that would return an empty
span, in which case that byte is included.
This is usually a good heuristic for generating error spans because the first token that cannot match anything is likely to be the start of another valid token.
Limitations
While Logos strives to have a feature complete regex implementation, there are
some limitations. Unicode word boundaries, some lookarounds, and other advanced
features not supported by the DFA matching engine in the regex crate are not
possible to match using Logos’ generated state machine.
However, attempting to use a missing feature will result in a compile-time
error. If your code compiles, the matcher behavior is exactly the same as the
regex crate.
Other issues
Logos’ support for regexes is feature complete, but errors can still exist. Some are found at compile time, and others will create wrong matches or panic.
If you ever feel like your patterns do not match the expected source slices, please check the GitHub issues. If no issue covers your problem, we encourage you to create a new issue, and document it as best as you can so that the issue can be reproduced locally.
Unicode support
By default, logos is Unicode aware. It accepts input in the form of a Rust
&str that is valid UTF-8 and it compiles its regular expressions to match
Unicode codepoints. When it returns spans for tokens, these spans are
guaranteed to not split UTF-8 codepoints. These behaviors can all be changed,
however.
Using &[u8] input
The easiest thing to change is how logos accepts an input. By adding the
#[logos(utf8 = false)] attribute to your token enum, you instruct logos to
accept a byte slice for input instead. This, by itself, doesn’t change matching
behavior at all. The regular expressions are all still compiled with Unicode
support, . matching a single character rather than a byte, etc. If all you
did was add that attribute and you called the lexer with
Token::lexer(input.as_bytes()), then you would get the exact same output as
before.
Matching bytes rather than Unicode codepoints
If you want to ignore Unicode altogether and match ASCII, raw bytes, or
whatever esoteric character encoding you want, you can compile your regular
expressions with Unicode mode off. This can be done by either removing the
Unicode flag manually with (?-u) in your regular expression, or if you supply
the pattern as a byte string, like #[regex(b"my.*pattern")] then logos will
turn off the flag for you. See the regex
docs for more
information.
Logos will automatically detect if any of your patterns can match a byte
sequence that is invalid UTF-8. If one exists and you haven’t set the lexer to
use &[u8] input, it will issue a compile error.
State machine codegen
The method of implementing the DFA state machine in Rust code can be changed by
enabling or disabling the crate feature state_machine_codegen. This has no
behavioral differences when enabled or disabled, it only affects performance
and stack memory usage.
Feature enabled
The state machine codegen creates an enum variant for each state, and puts the
state bodies in the arms of a match statement. The match statement is put
inside of a loop, and state transitions are implemented by assigning to the
current state variable and then continueing to the start of the loop again.
let mut state = State::State0;
loop {
match state {
State::State0 => {
match lexer.read() {
'a' => state = State::State1,
'b' => state = State::State2,
_ => return Token::Error,
}
}
// Etc...
}
}Feature Disabled
The tailcall code generation creates functions for each state, and state transitions are implemented by calling the next state’s function.
fn state0(lexer: Lexer, context: Context) -> Token {
match lexer.read() {
'a' => state1(lexer, context),
'b' => state2(lexer, context),
_ => Token::Error,
}
}
// Etc ...Considerations
The tail call code generation generates significantly faster code and is
therefore the default. However, until Rust gets guaranteed tail calls with the
become keyword, it is possible to overflow the stack using it. This usually
happens when many “skip” tokens are matched in a row. This can be solved by
wrapping your skip pattern in a repetition, though this is not always the case.
If you don’t want to worry about possible stack overflows, you can use the
state_machine_codegen feature.
Performance Explanation
Tail call code generation is faster because LLVM does not currently optimize switches within loops well. The resulting machine code usually has each state jump back to the top of the loop, where the next state is looked up in a jump table. In contrast, tail call generation usually results in an unconditional jump at the end of the state to the next state. While the unconditional jump is slightly better in terms of instruction count, the real advantage lies in the tail call code generation being much nicer to the branch predictor.
Potential Mitigations
There are a couple of things that would improve the quality of the code
generated by the state machine codegen. First, if you add the
-enable-dfa-jump-thread
LLVM pass to rustc, you end up with very similar machine code in both code
generators (but the state machine has the added benefit of no possibility of
stack overflows). This option can be added using a config.toml file
(example).
It is probably not a good idea to do this in production code, as adding new
LLVM passes to rustc increases the possibility of facing compiler bugs. There is
also the possibility of this optimization being added at the Rust level. This
is being explored by RFC 3720.
If that RFC is implemented, the logos state machine codegen could use the new
loop match construct to obtain a similar optimization.
Logos Version Migration Guide
This page contains guidance for migrating between versions of logos that have major breaking changes.
Changes in 0.16.0
Logos 0.16.0 was a very large update. As of this writing, the PR changed over 100 files and touches over 1000 lines of code. It fixed a number of long standing issues related to backtracking and matching state machine soundness.
The update also added some major new features and a handful of breaking changes.
New Features
- Dot repetitions such as
.*and.+are now supported. Due to the related supported pitfalls, they are disallowed by default, but can be used if you pass the attribute argumentallow_greedy = trueor if you make them non-greedy. For more information, see Common performance pitfalls. - Logos now precisely follows regex match semantics. Before 0.16.0, repetitions
were greedily followed, which would cause no matches where a match should have
been possible. For example, in 0.15.1, it is impossible to match the pattern
a*abecause allabytes are consumed by the repetition. This irregular behavior has been fixed in 0.16.0. The behavior should now be identical to theregexcrate with the following assumptions:- Every pattern behaves as if it has a start of input anchor (
^) prepended to it. - Unicode word boundaries, some lookaround, and other advanced features not supported by the DFA regex engine will cause a compile-time error because they cannot be matched by the state machine that logos generates.
- Every pattern behaves as if it has a start of input anchor (
- The error token semantics are now precisely defined. See Error semantics.
- The new
state_machine_codegenfeature. If you are experiencing issues with stack overflows, enabling this feature will solve them. It is slower than the default tailcall codegen, but it will never overflow the stack. See State machine codegen.
Breaking Changes
- The
ignore_ascii_caseattribute was removed. You can switch to using theignore_caseattribute, which also works on non-unicode patterns. If you explicitly want to ignore case for ASCII characters but not others, you will have to do it manually using character classes. See#[token]and#[regex]. - The
sourceattribute has been removed. You can now use theutf8attribute to select either&stror&[u8]as the source type. Custom source types are no longer supported. If you need this feature, you can either stay on0.15.1or contribute an implementation to Logos! For more information onutf8, see its#[logos].
Debugging
Instructions on how to debug your Logos lexer.
Visualizing Logos Graph
Logos works by creating a graph that gets derived from the tokens that you defined. This graph describes how the lexer moves through different states when processing input.
Hence, it may be beneficial during debugging to be able to visualize this graph, to understand how Logos will match the various tokens.
If we take this example:
use logos::Logos;
#[derive(Debug, Logos, PartialEq)]
enum Token {
// Tokens can be literal strings, of any length.
#[token("fast")]
Fast,
#[token(".")]
Period,
// Or regular expressions.
#[regex("[a-zA-Z]+")]
Text,
}
fn main() {
let input = "Create ridiculously fast Lexers.";
let mut lexer = Token::lexer(input);
while let Some(token) = lexer.next() {
println!("{:?}", token);
}
}and compile with the debug feature, we can see debugging information about
the regex compilation and resulting state machine. First, it outputs a list of
the “leaves”, or different patterns that can be matched by the state machine. A
leaf is generated for each #[token(...)] and #[regex(...)] attribute.
0: #[token("fast")] ::Fast (priority: 8)
1: #[token(".")] ::Period (priority: 2)
2: #[regex("[a-zA-Z]+")] ::Text (priority: 2)
Next, the debug representation of the DFA is printed. For more information on decoding this, see the regex-cli docs. Lastly, the actual graph that that the generated Rust code follows is printed (this is usually slightly different than the regex-automata graph due to various optimizations that are applied). For our above example, it looks like this:
state0 => StateData(early(2) ) {
A..=Z|a..=z => state0
}
state1 => StateData(early(2) ) {
A..=Z|a..=r|t..=z => state0
s => state2
}
state2 => StateData(early(2) ) {
A..=Z|a..=s|u..=z => state0
t => state3
}
state3 => StateData(early(0) ) {
A..=Z|a..=z => state0
}
state4 => StateData() {
A..=Z|a..=e|g..=z => state0
. => state5
f => state6
}
state5 => StateData(early(1) ) {
}
state6 => StateData(early(2) ) {
A..=Z|b..=z => state0
a => state1
}
Root node: State(4)
This graph can help us understand how our patterns are matched, and maybe understand why we have a bug at some point.
Let’s get started by trying to understand how Logos is matching the
. character, which we’ve tokenized as Token::Period.
We can begin our search by looking at state 4, as that is the root node.
We can see that if Logos matches a . it will jump => to state 5.
We can then follow that by looking at state5 which resolves leaf 1, which
we saw earlier as corresponding to the Token::Period variant.
Note
If you are curious why it says
early(1), that is because this is an early match. A “late” match means that the current character is not part of the returned token. Usually this is because the current character is the imaginary end-of-file character, used for matching patterns that end in$.
Logos would also continue to look for any matches past our . character.
However, since there is not another leaf that could possibly match, it instead
stops. This is indicated by the fact that there are no “next state” edges
within state5.
We also can try to identify how the token fast works by looking at 4,
first, and seeing that f will cause Logos to jump to 6, then a to 1,
s to 2, and finally, t to 3. In this state, you can see that there is a
match for leaf 0, but also a continuation to state0. This will be taken if
the lexer is passed something like faster, which will be eventually lexed to
a Token::Text token instead.
Visual Representation
Logos can generate Mermaid charts and DOT graphs to visualize the lexer’s state transitions.
Specify an export directory with the export_dir attribute to save these graphs:
#[derive(Logos)]
#[logos(export_dir = "path/to/export/dir")]
enum Token {
#[token("fast")]
Fast,
#[token(".")]
Period,
#[regex("[a-zA-Z]+")]
Text,
}You can also specify the name of the file to export to.
#[logos(export_dir = "export/graph.mmd")]To render the graphs, you can install a plugin in your IDE or use an online tool.
See the graphviz and mermaid documentations for more details.

Note
This graphviz graph has been modified with the graph attribute
rankdir="LR";to make it fit better on screen.
Enabling
To enable debugging output you can define a debug feature in your
Cargo.toml file, like this:
// Cargo.toml
[dependencies]
logos = { version = "1.2.3", features = ["debug"] }
Next, you can build your project with cargo build and
the output will contain a debug representation of your graph(s).
Unsafe Code
By default, Logos uses unsafe code to avoid unnecessary bounds checks while
accessing slices of the input Source.
This unsafe code also exists in the code generated by the Logos derive macro,
which generates a deterministic finite automaton (DFA). Reasoning about the correctness
of this generated code can be difficult - if the derivation of the DFA in Logos
is correct, then this generated code will be correct and any mistakes in implementation
would be caught given sufficient fuzz testing.
Use of unsafe code is the default as this typically provides the fastest parser.
Disabling Unsafe Code
However, for applications accepting untrusted input in a trusted context, this may not be a sufficient correctness justification.
For those applications which cannot tolerate unsafe code, the feature forbid_unsafe
may be enabled. This replaces unchecked accesses in the Logos crate with safe,
checked alternatives which will panic on out-of-bounds access rather than cause
undefined behavior. Additionally, code generated by the macro will not use the
unsafe keyword, so generated code may be used in a crates using the
#![forbid(unsafe_code)] attribute.
When the forbid-unsafe feature is added to a direct dependency on the Logos crate,
Feature Unification
ensures any transitive inclusion of Logos via other dependencies also have unsafe
code disabled.
Generally, disabling unsafe code will result in a slower parser.
However, making definitive statements about performance of safe-only code is difficult, as there are too many variables to consider between compiler optimizations, the specific grammar being parsed, and the target processor. The automated benchmarks of this crate show around a 10% slowdown in safe-only code at the time of this writing.
Partial lexing
It is sometimes useful to give to the lexer not the full input buffer, but only a prefix of it. For example, when lexing files that do not fit into memory.
For that Logos exposes the Lexer::new_partial function that is a variant of Lexer::new but return None if more data should be given to unambgiously recognize the next token.
Usage example
#![allow(unused)]
fn main() {
while !is_eof { // We run while we still have unread data
let mut lexer = Lexer::new_partial(buffer);
while let Some(token) = lexer.next() {
// Do something with the token
}
// We add more data to the buffer
extend_buffer_with_more_data(&mut buffer);
}
// We lex the last tokens with the usual lexer because the buffer is now filled to the end
let mut lexer = Lexer::new(buffer);
while let Some(token) = lexer.next() {
// Do something with the token
}
}This can be leverage to lex data from a Read or an AsyncRead instance without buffering everything into memory.
See the repo json_reader example for that.
Examples
The following examples are ordered by increasing level of complexity.
Brainfuck interpreter: Lexers are very powerful tools for parsing code programs into meaningful instructions. We show you how you can build an interpreter for the Brainfuck programming language under 100 lines of code!
Simple calculator: For a relatively large domain-specific language (DSL), or any programming language, implementing an interpreter typically involves converting the tokens generated by a lexer into an abstract syntax tree (AST) via a parser, and then evaluating it. We show you how you can build a simple calculator that evaluates arithmetic expressions by combining Logos and a parser generator library.
Simple array language: A one-dimensional array language using a lexer with an explicit source lifetime, so that the tokens created outlive the source, despite storing borrows.
JSON parser: We present a JSON parser written with Logos that does nice error reporting when invalid values are encountered.
JSON-borrowed parser: A variant of the previous parser, but that does not own its data.
String interpolation: Example on using context-dependent lexing to parse a simple language with string interpolation.
Brainfuck interpreter
In most programming languages, commands can be made of multiple program tokens, where a token is simply string slice that has a particular meaning for the language. For example, in Rust, the function signature pub fn main() could be split by the lexer into tokens pub, fn, main, (, and ). Then, the parser combines tokens into meaningful program instructions.
However, there exists programming languages that are so simple, such as Brainfuck, that each token can be mapped to a single instruction. There are actually 8 single-characters tokens:
/// Each [`Op`] variant is a single character.
#[derive(Debug, Logos)]
// skip all non-op characters
#[logos(skip(".|\n", priority = 0))]
enum Op {
/// Increment pointer.
#[token(">")]
IncPointer,
/// Decrement pointer.
#[token("<")]
DecPointer,
/// Increment data at pointer.
#[token("+")]
IncData,
/// Decrement data at pointer.
#[token("-")]
DecData,
/// Output data at pointer.
#[token(".")]
OutData,
/// Input (read) to data at pointer.
#[token(",")]
InpData,
/// Conditionally jump to matching `']'`.
#[token("[")]
CondJumpForward,
/// Conditionally jump to matching `'['`.
#[token("]")]
CondJumpBackward,
}All other characters must be ignored.
Once the tokens are obtained, a Brainfuck interpreter can be easily created using a Finite-state machine. For the sake of simplicity, we collected all the tokens into one vector called operations.
Now, creating an interpreter becomes straightforward1:
let mut i: usize = 0;
// True program execution.
loop {
match operations[i] {
Op::IncPointer => pointer += 1,
Op::DecPointer => pointer -= 1,
Op::IncData => data[pointer] = data[pointer].wrapping_add(1),
Op::DecData => data[pointer] = data[pointer].wrapping_sub(1),
Op::OutData => print_byte(data[pointer]),
Op::InpData => data[pointer] = read_byte(),
Op::CondJumpForward => {
if data[pointer] == 0 {
// Skip until matching end.
i = *pairs.get(&i).unwrap();
}
}
Op::CondJumpBackward => {
if data[pointer] != 0 {
// Go back to matching start.
i = *pairs_reverse.get(&i).unwrap();
}
}
}
i += 1;
if i >= len {
break;
}
}Finally, we provide you the full code that you should be able to run with2:
cargo run --example brainfuck examples/hello_word.bf
use logos::Logos;
use std::collections::HashMap;
use std::env;
use std::fs;
use std::io::{self, Read};
/// Each [`Op`] variant is a single character.
#[derive(Debug, Logos)]
// skip all non-op characters
#[logos(skip(".|\n", priority = 0))]
enum Op {
/// Increment pointer.
#[token(">")]
IncPointer,
/// Decrement pointer.
#[token("<")]
DecPointer,
/// Increment data at pointer.
#[token("+")]
IncData,
/// Decrement data at pointer.
#[token("-")]
DecData,
/// Output data at pointer.
#[token(".")]
OutData,
/// Input (read) to data at pointer.
#[token(",")]
InpData,
/// Conditionally jump to matching `']'`.
#[token("[")]
CondJumpForward,
/// Conditionally jump to matching `'['`.
#[token("]")]
CondJumpBackward,
}
/// Print one byte to the terminal.
#[inline(always)]
fn print_byte(byte: u8) {
print!("{}", byte as char);
}
/// Read one byte from the terminal.
#[inline(always)]
fn read_byte() -> u8 {
let mut input = [0u8; 1];
io::stdin()
.read_exact(&mut input)
.expect("An error occurred while reading byte!");
input[0]
}
/// Execute Brainfuck code from a string slice.
pub fn execute(code: &str) {
let operations: Vec<_> = Op::lexer(code).collect::<Result<_, _>>().unwrap();
let mut data = [0u8; 30_000]; // Minimum recommended size
let mut pointer: usize = 0;
let len = operations.len();
// We pre-process matching jump commands, and we create
// a mapping between them.
let mut queue = Vec::new();
let mut pairs = HashMap::new();
let mut pairs_reverse = HashMap::new();
for (i, op) in operations.iter().enumerate() {
match op {
Op::CondJumpForward => queue.push(i),
Op::CondJumpBackward => {
if let Some(start) = queue.pop() {
pairs.insert(start, i);
pairs_reverse.insert(i, start);
} else {
panic!(
"Unexpected conditional backward jump at position {}, does not match any '['",
i
);
}
}
_ => (),
}
}
if !queue.is_empty() {
panic!("Unmatched conditional forward jump at positions {:?}, expecting a closing ']' for each of them", queue);
}
let mut i: usize = 0;
// True program execution.
loop {
match operations[i] {
Op::IncPointer => pointer += 1,
Op::DecPointer => pointer -= 1,
Op::IncData => data[pointer] = data[pointer].wrapping_add(1),
Op::DecData => data[pointer] = data[pointer].wrapping_sub(1),
Op::OutData => print_byte(data[pointer]),
Op::InpData => data[pointer] = read_byte(),
Op::CondJumpForward => {
if data[pointer] == 0 {
// Skip until matching end.
i = *pairs.get(&i).unwrap();
}
}
Op::CondJumpBackward => {
if data[pointer] != 0 {
// Go back to matching start.
i = *pairs_reverse.get(&i).unwrap();
}
}
}
i += 1;
if i >= len {
break;
}
}
}
fn main() {
let src = fs::read_to_string(env::args().nth(1).expect("Expected file argument"))
.expect("Failed to read file");
execute(src.as_str());
}-
There is a small trick to make it easy. As it can be seen in the full code, we first perform a check that all beginning loops (
'[') have a matching end (']'). This way, we can create two maps,pairsandpairs_reverse, to easily jump back and forth between them. ↩ -
You first need to clone this repository. ↩
Simple calculator
This page (including the images) was contributed by ynn.
When you implement an interpreter for a domain-specific language (DSL), or any programming language, the process typically involves the following steps:
-
Lexing: Splitting the input stream (i.e., source code string) into tokens via a lexer.
-
Parsing: Converting the tokens into an abstract syntax tree (AST) via a parser.
-
Evaluation: Evaluating the AST to produce the result.
In this example, we implement a simple calculator that evaluates arithmetic expressions such as 1 + 2 * 3 or ((1 + 2) * 3 + 4) * 2 + 4 / 3.
We use logos as the lexer generator and chumsky as the parser library.
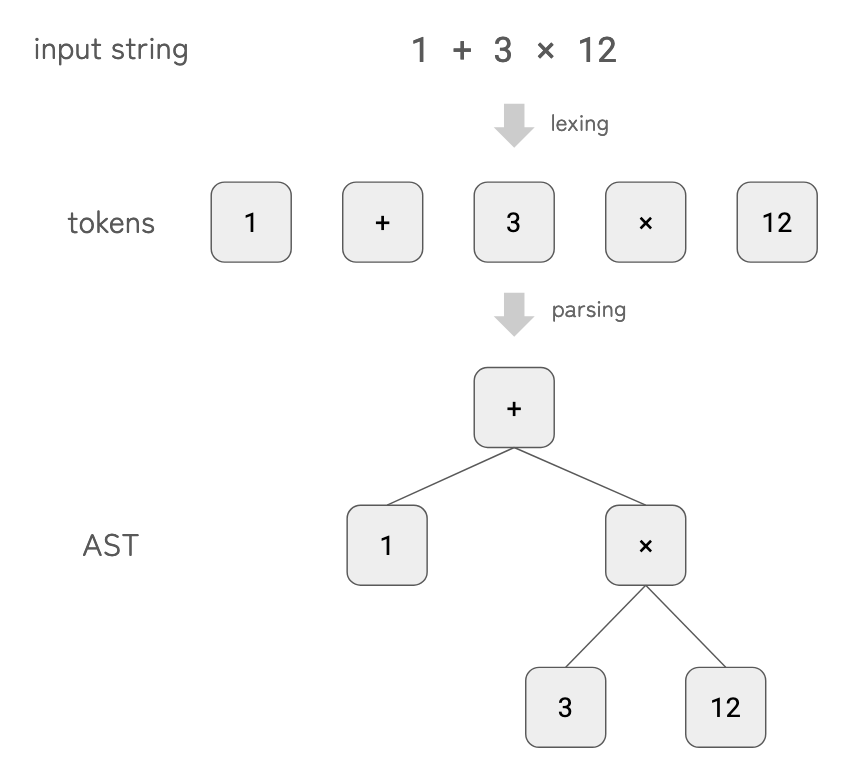
1. Try It
Before diving into the implementation details, let’s play with it1.
$ cargo run --example calculator '1 + 7 * (3 - 4) / 2'
Output:
[AST]
Add(
Int(
1,
),
Div(
Mul(
Int(
7,
),
Sub(
Int(
3,
),
Int(
4,
),
),
),
Int(
2,
),
),
)
[result]
-2
Full source code
use std::env;
use chumsky::prelude::*;
use logos::Logos;
#[derive(Logos, Debug, PartialEq, Eq, Hash, Clone)]
#[logos(skip r"[ \t\n]+")]
#[logos(error = String)]
enum Token {
#[token("+")]
Plus,
#[token("-")]
Minus,
#[token("*")]
Multiply,
#[token("/")]
Divide,
#[token("(")]
LParen,
#[token(")")]
RParen,
#[regex("[0-9]+", |lex| lex.slice().parse::<isize>().unwrap())]
Integer(isize),
}
#[derive(Debug)]
enum Expr {
// Integer literal.
Int(isize),
// Unary minus.
Neg(Box<Expr>),
// Binary operators.
Add(Box<Expr>, Box<Expr>),
Sub(Box<Expr>, Box<Expr>),
Mul(Box<Expr>, Box<Expr>),
Div(Box<Expr>, Box<Expr>),
}
impl Expr {
fn eval(&self) -> isize {
match self {
Expr::Int(n) => *n,
Expr::Neg(rhs) => -rhs.eval(),
Expr::Add(lhs, rhs) => lhs.eval() + rhs.eval(),
Expr::Sub(lhs, rhs) => lhs.eval() - rhs.eval(),
Expr::Mul(lhs, rhs) => lhs.eval() * rhs.eval(),
Expr::Div(lhs, rhs) => lhs.eval() / rhs.eval(),
}
}
}
#[allow(clippy::let_and_return)]
fn parser<'src>(
) -> impl Parser<'src, &'src [Token], Expr, chumsky::extra::Err<chumsky::error::Simple<'src, Token>>>
{
recursive(|p| {
let atom = {
let parenthesized = p
.clone()
.delimited_by(just(Token::LParen), just(Token::RParen));
let integer = select! {
Token::Integer(n) => Expr::Int(n),
};
parenthesized.or(integer)
};
let unary = just(Token::Minus)
.repeated()
.foldr(atom, |_op, rhs| Expr::Neg(Box::new(rhs)));
let binary_1 = unary.clone().foldl(
just(Token::Multiply)
.or(just(Token::Divide))
.then(unary)
.repeated(),
|lhs, (op, rhs)| match op {
Token::Multiply => Expr::Mul(Box::new(lhs), Box::new(rhs)),
Token::Divide => Expr::Div(Box::new(lhs), Box::new(rhs)),
_ => unreachable!(),
},
);
let binary_2 = binary_1.clone().foldl(
just(Token::Plus)
.or(just(Token::Minus))
.then(binary_1)
.repeated(),
|lhs, (op, rhs)| match op {
Token::Plus => Expr::Add(Box::new(lhs), Box::new(rhs)),
Token::Minus => Expr::Sub(Box::new(lhs), Box::new(rhs)),
_ => unreachable!(),
},
);
binary_2
})
}
fn main() {
//reads the input expression from the command line
let input = env::args()
.nth(1)
.expect("Expected expression argument (e.g. `1 + 7 * (3 - 4) / 5`)");
//creates a lexer instance from the input
let lexer = Token::lexer(&input);
//splits the input into tokens, using the lexer
let mut tokens = vec![];
for (token, span) in lexer.spanned() {
match token {
Ok(token) => tokens.push(token),
Err(e) => {
println!("lexer error at {:?}: {}", span, e);
return;
}
}
}
//parses the tokens to construct an AST
let ast = match parser().parse(&tokens).into_result() {
Ok(expr) => {
println!("[AST]\n{:#?}", expr);
expr
}
Err(e) => {
println!("parse error: {:#?}", e);
return;
}
};
//evaluates the AST to get the result
println!("\n[result]\n{}", ast.eval());
}2. Lexer
Our calculator supports the following tokens:
-
Integer literals:
0,1,15, etc; -
Unary operator:
-; -
Binary operators:
+,-,*,/; -
Parenthesized expressions:
(3 + 5) * 2,((1 + 2) * 3 + 4) * 2 + 3 / 2, etc.
#[derive(Logos, Debug, PartialEq, Eq, Hash, Clone)]
#[logos(skip r"[ \t\n]+")]
#[logos(error = String)]
enum Token {
#[token("+")]
Plus,
#[token("-")]
Minus,
#[token("*")]
Multiply,
#[token("/")]
Divide,
#[token("(")]
LParen,
#[token(")")]
RParen,
#[regex("[0-9]+", |lex| lex.slice().parse::<isize>().unwrap())]
Integer(isize),
}3. Parser
While it is easy enough to manually implement a parser in this case (e.g., Pratt parsing), let’s just use the chumsky crate, which is a popular parser combinator library in Rust.
3.1 AST Definition
First, we define the AST.
#[derive(Debug)]
enum Expr {
// Integer literal.
Int(isize),
// Unary minus.
Neg(Box<Expr>),
// Binary operators.
Add(Box<Expr>, Box<Expr>),
Sub(Box<Expr>, Box<Expr>),
Mul(Box<Expr>, Box<Expr>),
Div(Box<Expr>, Box<Expr>),
}Note that
-
We name the
enumnotASTbutExprbecause an AST is just nested expressions. -
There is no
Parenthesizedvariant because parentheses only affect the order of operations (i.e., precedence), which is reflected in the AST structure. -
Boxis used as a recursiveenumis not allowed in Rust.
3.2 Parser Implementation
Next, we define the parser. The code may look a bit complicated if you are not familiar with parser combinator libraries, but it is actually quite simple. See Chumsky’s official tutorial for the details.
fn parser<'src>(
) -> impl Parser<'src, &'src [Token], Expr, chumsky::extra::Err<chumsky::error::Simple<'src, Token>>>
{
recursive(|p| {
let atom = {
let parenthesized = p
.clone()
.delimited_by(just(Token::LParen), just(Token::RParen));
let integer = select! {
Token::Integer(n) => Expr::Int(n),
};
parenthesized.or(integer)
};
let unary = just(Token::Minus)
.repeated()
.foldr(atom, |_op, rhs| Expr::Neg(Box::new(rhs)));
let binary_1 = unary.clone().foldl(
just(Token::Multiply)
.or(just(Token::Divide))
.then(unary)
.repeated(),
|lhs, (op, rhs)| match op {
Token::Multiply => Expr::Mul(Box::new(lhs), Box::new(rhs)),
Token::Divide => Expr::Div(Box::new(lhs), Box::new(rhs)),
_ => unreachable!(),
},
);
let binary_2 = binary_1.clone().foldl(
just(Token::Plus)
.or(just(Token::Minus))
.then(binary_1)
.repeated(),
|lhs, (op, rhs)| match op {
Token::Plus => Expr::Add(Box::new(lhs), Box::new(rhs)),
Token::Minus => Expr::Sub(Box::new(lhs), Box::new(rhs)),
_ => unreachable!(),
},
);
binary_2
})
}4. Evaluator
Evaluating the AST is straightforward. We just implement it using depth-first search (DFS) such that the mathematical operations are processed in the correct order.
impl Expr {
fn eval(&self) -> isize {
match self {
Expr::Int(n) => *n,
Expr::Neg(rhs) => -rhs.eval(),
Expr::Add(lhs, rhs) => lhs.eval() + rhs.eval(),
Expr::Sub(lhs, rhs) => lhs.eval() - rhs.eval(),
Expr::Mul(lhs, rhs) => lhs.eval() * rhs.eval(),
Expr::Div(lhs, rhs) => lhs.eval() / rhs.eval(),
}
}
}Example
Evaluating 1 + 3 * 12 will proceed as below.
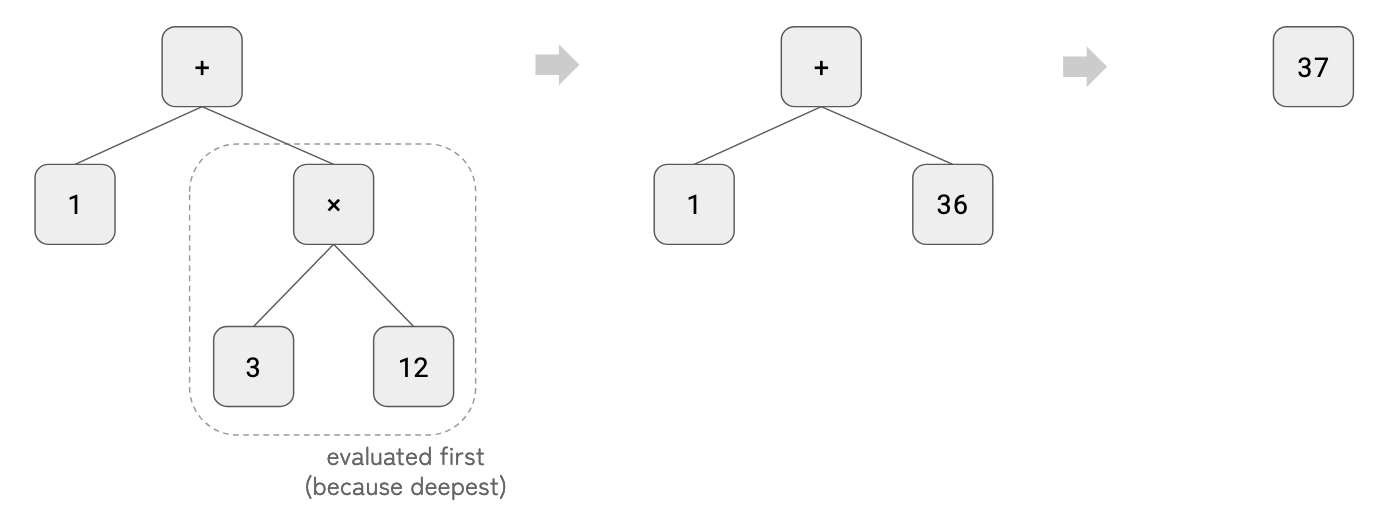
5. main() Function
Finally, we put everything together in the main() function.
fn main() {
//reads the input expression from the command line
let input = env::args()
.nth(1)
.expect("Expected expression argument (e.g. `1 + 7 * (3 - 4) / 5`)");
//creates a lexer instance from the input
let lexer = Token::lexer(&input);
//splits the input into tokens, using the lexer
let mut tokens = vec![];
for (token, span) in lexer.spanned() {
match token {
Ok(token) => tokens.push(token),
Err(e) => {
println!("lexer error at {:?}: {}", span, e);
return;
}
}
}
//parses the tokens to construct an AST
let ast = match parser().parse(&tokens).into_result() {
Ok(expr) => {
println!("[AST]\n{:#?}", expr);
expr
}
Err(e) => {
println!("parse error: {:#?}", e);
return;
}
};
//evaluates the AST to get the result
println!("\n[result]\n{}", ast.eval());
}6. Extend the Calculator
Now that you’ve implemented a basic calculator, try extending its functionality with the following tasks:
-
Handle zero-division gracefully: The current evaluator panics when zero-division occurs. Change the return type of the evaluator from
isizetoResult<isize, String>, making it possible to return an error message. -
Add support for the modulo operator (
%): Update the lexer, parser, and evaluator to handle expressions like10 % 3. -
Add support for built-in functions: Implement built-in functions such as
abs(x),pow(x, y)orrand().
-
You first need to clone this repository. ↩
Simple array language
Programs written in array languages manipulate
arrays of values as their primary data. In this example, we create a simple one-dimensional1
array language. Programs are interpreted as a sequence of instructions on an initially empty array.
Writing a number or variable appends it to the array, while sum (+) and product (*)
combine all the numbers in the array into a single value, making the array a singleton.
This example demonstrates how explicit lifetime specification
can be used to create lexers which output tokens with (non-static) lifetimes that outlive the source.
These lexers all share the same (immutable) state across different threads, without any cloning or Arcs!
Example program
There is an example program you can run with2:
cargo run --example array_language examples/array_program.txt
Lexing
The variable environment maps variable names to values.
type Environment = HashMap<String, Vec<i128>>;The token type is parameterized by the lifetime 'a, which is used in the lexer extras
as the lifetime of the borrow of the variable environment.
#[derive(Debug, Logos)]
#[logos(lifetime = none)]
#[logos(error(LexingError<'s>, |lex| LexingError::UnknownSymbol(lex.slice())))]
#[logos(extras = &'a Environment)]
#[logos(skip " +")]
enum Token<'a> {
#[regex(r"\-?[0-9]+", number_callback)]
Number(i128),
#[regex(r"[[:alpha:]][[:alnum:]]*", var_callback)]
Array(&'a [i128]),
#[token("*")]
Product,
#[token("+")]
Sum,
#[token("~")]
Reverse,
}The lexer uses two callbacks:
/// Parse lexer slice as an i128
fn number_callback<'s>(lex: &mut Lexer<'s, Token>) -> Result<i128, LexingError<'s>> {
let source = lex.slice();
let res = source.parse();
res.map_err(|err| LexingError::InvalidInteger { err, source })
}
/// Look up the lexer slice in the variable environment,
/// yielding a borrow of the variable's value.
fn var_callback<'s, 'a>(lex: &mut Lexer<'s, Token<'a>>) -> Result<&'a [i128], LexingError<'s>> {
match lex.extras.get(lex.slice()) {
Some(arr) => Ok(arr.as_slice()),
None => Err(LexingError::UnknownVariable(lex.slice())),
}
}The #[logos(lifetime = none)] attribute explicitly specifies that 'a is not the
source lifetime3. This means that the borrow of the environment (and thus the tokens
the lexer produces) is independent of the source. Logos creates a 's lifetime for the
source instead, which is used in the error type to store the slice causing the error:
/// Token error type, tied to the lifetime of the source.
#[derive(Default, Debug, Clone, PartialEq)]
enum LexingError<'s> {
UnknownSymbol(&'s str),
InvalidInteger {
err: ParseIntError,
source: &'s str,
},
UnknownVariable(&'s str),
#[default]
Other,
}A file is lexed by creating a separate lexer for each line of the file and combining the results.
/// Open the given file and lex each line, returning the results.
/// For each line, a lexer is created on a new thread.
/// The environment is shared between all lexers.
fn lex_file<'a>(path: &Path, env: &'a Environment) -> Vec<Result<Vec<Token<'a>>, String>> {
let source = std::fs::read_to_string(path).expect("Failed to read file");
std::thread::scope(|s| {
let mut handles = Vec::new();
for line in source.lines() {
handles.push(s.spawn(|| {
let lexer = Token::lexer_with_extras(line, env);
// Convert the lexer errors to strings before returning,
// because the source is scoped to this function.
lexer.map(|res| res.map_err(|e| e.to_string())).collect()
}));
}
handles.into_iter().flat_map(|h| h.join()).collect()
})
}Scoped threads allow non-static borrows of variables outside the thread. Here, we use
this ability to store a borrow of the variable environment in the extras of each lexer.
This allows us to lex each line in parallel, sharing the variable environment between
threads without needing to clone it or wrap it in an Arc. Since the token lifetime
is independent of the source, the created tokens can be returned as is.
Note
Lexing each line of a file in parallel is done as an example and is probably a bad idea in a real program. It’s more likely that you would want to lex multiple files in parallel.
Evaluation
Each token is evaluated by updating an accumulator, which starts empty. A number or array token has its contents appended to the accumulator, whereas the sum and product operators combine all the numbers in the accumulator into a singleton. Once all tokens have been evaluated sequentially, the final accumulator is returned.
/// Evaluate a sequence of tokens to produce an array.
fn evaluate(tokens: &[Token]) -> Vec<i128> {
let mut accumulator = Vec::new();
for tok in tokens {
match *tok {
Token::Number(n) => accumulator.push(n),
Token::Array(arr) => accumulator.extend(arr),
Token::Product => {
let n = accumulator.drain(..).product();
accumulator.push(n);
}
Token::Sum => {
let n = accumulator.drain(..).sum();
accumulator.push(n);
}
Token::Reverse => accumulator.reverse(),
}
}
accumulator
}The lines in the input file are evaluated sequentially, printing the returned accumulator.
Full code
use logos::{Lexer, Logos};
use std::collections::HashMap;
use std::fmt::Display;
use std::num::ParseIntError;
use std::path::Path;
/// Token error type, tied to the lifetime of the source.
#[derive(Default, Debug, Clone, PartialEq)]
enum LexingError<'s> {
UnknownSymbol(&'s str),
InvalidInteger {
err: ParseIntError,
source: &'s str,
},
UnknownVariable(&'s str),
#[default]
Other,
}
impl Display for LexingError<'_> {
fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result {
match self {
Self::UnknownSymbol(s) => write!(f, "unknown symbol `{s}`"),
Self::InvalidInteger { err, source } => {
write!(f, "int error in source `{source}`: {err}")
}
Self::UnknownVariable(s) => write!(f, "unknown variable `{s}`"),
Self::Other => write!(f, "unknown error"),
}
}
}
type Environment = HashMap<String, Vec<i128>>;
/// Parse lexer slice as an i128
fn number_callback<'s>(lex: &mut Lexer<'s, Token>) -> Result<i128, LexingError<'s>> {
let source = lex.slice();
let res = source.parse();
res.map_err(|err| LexingError::InvalidInteger { err, source })
}
/// Look up the lexer slice in the variable environment,
/// yielding a borrow of the variable's value.
fn var_callback<'s, 'a>(lex: &mut Lexer<'s, Token<'a>>) -> Result<&'a [i128], LexingError<'s>> {
match lex.extras.get(lex.slice()) {
Some(arr) => Ok(arr.as_slice()),
None => Err(LexingError::UnknownVariable(lex.slice())),
}
}
#[derive(Debug, Logos)]
#[logos(lifetime = none)]
#[logos(error(LexingError<'s>, |lex| LexingError::UnknownSymbol(lex.slice())))]
#[logos(extras = &'a Environment)]
#[logos(skip " +")]
enum Token<'a> {
#[regex(r"\-?[0-9]+", number_callback)]
Number(i128),
#[regex(r"[[:alpha:]][[:alnum:]]*", var_callback)]
Array(&'a [i128]),
#[token("*")]
Product,
#[token("+")]
Sum,
#[token("~")]
Reverse,
}
/// Evaluate a sequence of tokens to produce an array.
fn evaluate(tokens: &[Token]) -> Vec<i128> {
let mut accumulator = Vec::new();
for tok in tokens {
match *tok {
Token::Number(n) => accumulator.push(n),
Token::Array(arr) => accumulator.extend(arr),
Token::Product => {
let n = accumulator.drain(..).product();
accumulator.push(n);
}
Token::Sum => {
let n = accumulator.drain(..).sum();
accumulator.push(n);
}
Token::Reverse => accumulator.reverse(),
}
}
accumulator
}
/// Open the given file and lex each line, returning the results.
/// For each line, a lexer is created on a new thread.
/// The environment is shared between all lexers.
fn lex_file<'a>(path: &Path, env: &'a Environment) -> Vec<Result<Vec<Token<'a>>, String>> {
let source = std::fs::read_to_string(path).expect("Failed to read file");
std::thread::scope(|s| {
let mut handles = Vec::new();
for line in source.lines() {
handles.push(s.spawn(|| {
let lexer = Token::lexer_with_extras(line, env);
// Convert the lexer errors to strings before returning,
// because the source is scoped to this function.
lexer.map(|res| res.map_err(|e| e.to_string())).collect()
}));
}
handles.into_iter().flat_map(|h| h.join()).collect()
})
}
fn main() {
let filename = std::env::args().nth(1).expect("Expected file argument");
let env = Environment::from([
("NAT".to_owned(), (1..=10).collect()),
("EVEN".to_owned(), (2..=20).step_by(2).collect()),
("ODD".to_owned(), (1..=20).step_by(2).collect()),
("PRIME".to_owned(), vec![2, 3, 5, 7, 11, 13, 17, 19, 23, 29]),
("FIB".to_owned(), vec![0, 1, 1, 2, 3, 5, 8, 13, 21, 34]),
("POW2".to_owned(), (0..=10).map(|n| 2i128.pow(n)).collect()),
]);
let results = lex_file(Path::new(&filename), &env);
for res in &results {
match res {
Ok(tokens) => {
let numbers = evaluate(tokens).into_iter().map(|n| n.to_string());
println!("[{}]", numbers.collect::<Vec<_>>().join(", "));
}
Err(s) => eprintln!("{s}"),
}
}
}-
Arrays can only contain numbers, not other arrays. ↩
-
You first need to clone this repository. ↩
-
Without the attribute, Logos will assume that
'ais the source lifetime. ↩
JSON parser
JSON is a widely used format for exchanging data between formats, while being human-readable.
Possible values are defined recursively and can be any of the following:
/// Represent any valid JSON value.
#[allow(unused)]
#[derive(Debug)]
enum Value {
/// null.
Null,
/// true or false.
Bool(bool),
/// Any floating point number.
Number(f64),
/// Any quoted string.
String(String),
/// An array of values
Array(Vec<Value>),
/// An dictionary mapping keys and values.
Object(HashMap<String, Value>),
}Object are delimited with braces { and }, arrays with brackets [ and ], and values with commas ,. Newlines, tabs or spaces should be ignored by the lexer.
Knowing that, we can construct a lexer with Logos that will identify all those cases:
/// All meaningful JSON tokens.
///
/// > NOTE: regexes for [`Token::Number`] and [`Token::String`] may not
/// > catch all possible values, especially for strings. If you find
/// > errors, please report them so that we can improve the regex.
#[derive(Debug, Logos)]
#[logos(skip r"[ \t\r\n\f]+")]
enum Token {
#[token("false", |_| false)]
#[token("true", |_| true)]
Bool(bool),
#[token("{")]
BraceOpen,
#[token("}")]
BraceClose,
#[token("[")]
BracketOpen,
#[token("]")]
BracketClose,
#[token(":")]
Colon,
#[token(",")]
Comma,
#[token("null")]
Null,
#[regex(r"-?(?:0|[1-9]\d*)(?:\.\d+)?(?:[eE][+-]?\d+)?", |lex| lex.slice().parse::<f64>().unwrap())]
Number(f64),
#[regex(r#""([^"\\\x00-\x1F]|\\(["\\bnfrt/]|u[a-fA-F0-9]{4}))*""#, |lex| lex.slice().to_owned())]
String(String),
}Note
The hardest part is to define valid regexes for
NumberandStringvariants. The present solution was inspired by this stackoverflow thread and checked against the JSON specification.
Once we have our tokens, we must parse them into actual JSON values. We will proceed be creating 3 functions:
parse_valuefor parsing any JSON object, without prior knowledge of its type;parse_arrayfor parsing an array, assuming we matched[;- and
parse_objectfor parsing an object, assuming we matched{.
Starting with parsing an arbitrary value, we can easily obtain the four scalar types, Bool, Null, Number, and String, while we will call the next functions for arrays and objects parsing.
/// Parse a token stream into a JSON value.
fn parse_value(lexer: &mut Lexer<'_, Token>) -> Result<Value> {
if let Some(token) = lexer.next() {
match token {
Ok(Token::Bool(b)) => Ok(Value::Bool(b)),
Ok(Token::BraceOpen) => parse_object(lexer),
Ok(Token::BracketOpen) => parse_array(lexer),
Ok(Token::Null) => Ok(Value::Null),
Ok(Token::Number(n)) => Ok(Value::Number(n)),
Ok(Token::String(s)) => Ok(Value::String(s)),
_ => Err((
"unexpected token here (context: value)".to_owned(),
lexer.span(),
)),
}
} else {
Err(("empty values are not allowed".to_owned(), lexer.span()))
}
}To parse an array, we simply loop between tokens, alternating between parsing values and commas, until a closing bracket is found.
/// Parse a token stream into an array and return when
/// a valid terminator is found.
///
/// > NOTE: we assume '[' was consumed.
fn parse_array(lexer: &mut Lexer<'_, Token>) -> Result<Value> {
let mut array = Vec::new();
let span = lexer.span();
let mut awaits_comma = false;
let mut awaits_value = false;
while let Some(token) = lexer.next() {
match token {
Ok(Token::Bool(b)) if !awaits_comma => {
array.push(Value::Bool(b));
awaits_value = false;
}
Ok(Token::BraceOpen) if !awaits_comma => {
let object = parse_object(lexer)?;
array.push(object);
awaits_value = false;
}
Ok(Token::BracketOpen) if !awaits_comma => {
let sub_array = parse_array(lexer)?;
array.push(sub_array);
awaits_value = false;
}
Ok(Token::BracketClose) if !awaits_value => return Ok(Value::Array(array)),
Ok(Token::Comma) if awaits_comma => awaits_value = true,
Ok(Token::Null) if !awaits_comma => {
array.push(Value::Null);
awaits_value = false
}
Ok(Token::Number(n)) if !awaits_comma => {
array.push(Value::Number(n));
awaits_value = false;
}
Ok(Token::String(s)) if !awaits_comma => {
array.push(Value::String(s));
awaits_value = false;
}
_ => {
return Err((
"unexpected token here (context: array)".to_owned(),
lexer.span(),
))
}
}
awaits_comma = !awaits_value;
}
Err(("unmatched opening bracket defined here".to_owned(), span))
}A similar approach is used for objects, where the only difference is that we expect (key, value) pairs, separated by a colon.
/// Parse a token stream into an object and return when
/// a valid terminator is found.
///
/// > NOTE: we assume '{' was consumed.
fn parse_object(lexer: &mut Lexer<'_, Token>) -> Result<Value> {
let mut map = HashMap::new();
let span = lexer.span();
let mut awaits_comma = false;
let mut awaits_key = false;
while let Some(token) = lexer.next() {
match token {
Ok(Token::BraceClose) if !awaits_key => return Ok(Value::Object(map)),
Ok(Token::Comma) if awaits_comma => awaits_key = true,
Ok(Token::String(key)) if !awaits_comma => {
match lexer.next() {
Some(Ok(Token::Colon)) => (),
_ => {
return Err((
"unexpected token here, expecting ':'".to_owned(),
lexer.span(),
))
}
}
let value = parse_value(lexer)?;
map.insert(key, value);
awaits_key = false;
}
_ => {
return Err((
"unexpected token here (context: object)".to_owned(),
lexer.span(),
))
}
}
awaits_comma = !awaits_key;
}
Err(("unmatched opening brace defined here".to_owned(), span))
}Finally, we provide you the full code that you should be able to run with[^1]:
cargo run --example json examples/example.json
[^1] You first need to clone this repository.
use logos::{Lexer, Logos, Span};
use std::collections::HashMap;
use std::env;
use std::fs;
type Error = (String, Span);
type Result<T> = std::result::Result<T, Error>;
/// All meaningful JSON tokens.
///
/// > NOTE: regexes for [`Token::Number`] and [`Token::String`] may not
/// > catch all possible values, especially for strings. If you find
/// > errors, please report them so that we can improve the regex.
#[derive(Debug, Logos)]
#[logos(skip r"[ \t\r\n\f]+")]
enum Token {
#[token("false", |_| false)]
#[token("true", |_| true)]
Bool(bool),
#[token("{")]
BraceOpen,
#[token("}")]
BraceClose,
#[token("[")]
BracketOpen,
#[token("]")]
BracketClose,
#[token(":")]
Colon,
#[token(",")]
Comma,
#[token("null")]
Null,
#[regex(r"-?(?:0|[1-9]\d*)(?:\.\d+)?(?:[eE][+-]?\d+)?", |lex| lex.slice().parse::<f64>().unwrap())]
Number(f64),
#[regex(r#""([^"\\\x00-\x1F]|\\(["\\bnfrt/]|u[a-fA-F0-9]{4}))*""#, |lex| lex.slice().to_owned())]
String(String),
}
/// Represent any valid JSON value.
#[allow(unused)]
#[derive(Debug)]
enum Value {
/// null.
Null,
/// true or false.
Bool(bool),
/// Any floating point number.
Number(f64),
/// Any quoted string.
String(String),
/// An array of values
Array(Vec<Value>),
/// An dictionary mapping keys and values.
Object(HashMap<String, Value>),
}
/// Parse a token stream into a JSON value.
fn parse_value(lexer: &mut Lexer<'_, Token>) -> Result<Value> {
if let Some(token) = lexer.next() {
match token {
Ok(Token::Bool(b)) => Ok(Value::Bool(b)),
Ok(Token::BraceOpen) => parse_object(lexer),
Ok(Token::BracketOpen) => parse_array(lexer),
Ok(Token::Null) => Ok(Value::Null),
Ok(Token::Number(n)) => Ok(Value::Number(n)),
Ok(Token::String(s)) => Ok(Value::String(s)),
_ => Err((
"unexpected token here (context: value)".to_owned(),
lexer.span(),
)),
}
} else {
Err(("empty values are not allowed".to_owned(), lexer.span()))
}
}
/// Parse a token stream into an array and return when
/// a valid terminator is found.
///
/// > NOTE: we assume '[' was consumed.
fn parse_array(lexer: &mut Lexer<'_, Token>) -> Result<Value> {
let mut array = Vec::new();
let span = lexer.span();
let mut awaits_comma = false;
let mut awaits_value = false;
while let Some(token) = lexer.next() {
match token {
Ok(Token::Bool(b)) if !awaits_comma => {
array.push(Value::Bool(b));
awaits_value = false;
}
Ok(Token::BraceOpen) if !awaits_comma => {
let object = parse_object(lexer)?;
array.push(object);
awaits_value = false;
}
Ok(Token::BracketOpen) if !awaits_comma => {
let sub_array = parse_array(lexer)?;
array.push(sub_array);
awaits_value = false;
}
Ok(Token::BracketClose) if !awaits_value => return Ok(Value::Array(array)),
Ok(Token::Comma) if awaits_comma => awaits_value = true,
Ok(Token::Null) if !awaits_comma => {
array.push(Value::Null);
awaits_value = false
}
Ok(Token::Number(n)) if !awaits_comma => {
array.push(Value::Number(n));
awaits_value = false;
}
Ok(Token::String(s)) if !awaits_comma => {
array.push(Value::String(s));
awaits_value = false;
}
_ => {
return Err((
"unexpected token here (context: array)".to_owned(),
lexer.span(),
))
}
}
awaits_comma = !awaits_value;
}
Err(("unmatched opening bracket defined here".to_owned(), span))
}
/// Parse a token stream into an object and return when
/// a valid terminator is found.
///
/// > NOTE: we assume '{' was consumed.
fn parse_object(lexer: &mut Lexer<'_, Token>) -> Result<Value> {
let mut map = HashMap::new();
let span = lexer.span();
let mut awaits_comma = false;
let mut awaits_key = false;
while let Some(token) = lexer.next() {
match token {
Ok(Token::BraceClose) if !awaits_key => return Ok(Value::Object(map)),
Ok(Token::Comma) if awaits_comma => awaits_key = true,
Ok(Token::String(key)) if !awaits_comma => {
match lexer.next() {
Some(Ok(Token::Colon)) => (),
_ => {
return Err((
"unexpected token here, expecting ':'".to_owned(),
lexer.span(),
))
}
}
let value = parse_value(lexer)?;
map.insert(key, value);
awaits_key = false;
}
_ => {
return Err((
"unexpected token here (context: object)".to_owned(),
lexer.span(),
))
}
}
awaits_comma = !awaits_key;
}
Err(("unmatched opening brace defined here".to_owned(), span))
}
fn main() {
let filename = env::args().nth(1).expect("Expected file argument");
let src = fs::read_to_string(&filename).expect("Failed to read file");
let mut lexer = Token::lexer(src.as_str());
match parse_value(&mut lexer) {
Ok(value) => println!("{:#?}", value),
Err((msg, span)) => {
use ariadne::{ColorGenerator, Label, Report, ReportKind, Source};
let mut colors = ColorGenerator::new();
let a = colors.next();
Report::build(ReportKind::Error, &filename, 12)
.with_message("Invalid JSON".to_string())
.with_label(
Label::new((&filename, span))
.with_message(msg)
.with_color(a),
)
.finish()
.eprint((&filename, Source::from(src)))
.unwrap();
}
}
}JSON parser with borrowed values
The previous parser owned its data by allocating strings. This can require quite some memory space, and using borrowed string slices can help use saving space, while also maybe increasing performances.
If you are familiar with Rust’s concept of lifetimes,
using &str string slices instead of owned String
is straightforward:
@ 33c29
- enum Token {
+ enum Token<'source> {
@ 62,63c58,59
- #[regex(r#""([^"\\\x00-\x1F]|\\(["\\bnfrt/]|u[a-fA-F0-9]{4}))*""#, |lex| lex.slice().to_owned())]
- String(String),
+ #[regex(r#""([^"\\\x00-\x1F]|\\(["\\bnfrt/]|u[a-fA-F0-9]{4}))*""#, |lex| lex.slice())]
+ String(&'source str),
@ 70c66
- enum Value {
+ enum Value<'source> {
@ 78c74
- String(String),
+ String(&'source str),
@ 80c76
- Array(Vec<Value>),
+ Array(Vec<Value<'source>>),
@ 82c78
- Object(HashMap<String, Value>),
+ Object(HashMap<&'source str, Value<'source>>),
@ 88c84
- fn parse_value<'source>(lexer: &mut Lexer<'source, Token>) -> Result<Value> {
+ fn parse_value<'source>(lexer: &mut Lexer<'source, Token<'source>>) -> Result<Value<'source>> {
@ 113c109
- fn parse_array<'source>(lexer: &mut Lexer<'source, Token>) -> Result<Value> {
+ fn parse_array<'source>(lexer: &mut Lexer<'source, Token<'source>>) -> Result<Value<'source>> {
@ 167c163
- fn parse_object<'source>(lexer: &mut Lexer<'source, Token>) -> Result<Value> {
+ fn parse_object<'source>(lexer: &mut Lexer<'source, Token<'source>>) -> Result<Value<'source>> {
The above code shows the lines you need to change from the previous example to use borrowed data.
Finally, we provide you the full code that you should be able to run with[^1]:
cargo run --example json-borrowed examples/example.json
[^1] You first need to clone this repository.
use logos::{Lexer, Logos, Span};
use std::collections::HashMap;
use std::env;
use std::fs;
type Error = (String, Span);
type Result<T> = std::result::Result<T, Error>;
/// All meaningful JSON tokens.
///
/// > NOTE: regexes for [`Token::Number`] and [`Token::String`] may not
/// > catch all possible values, especially for strings. If you find
/// > errors, please report them so that we can improve the regex.
#[derive(Debug, Logos)]
#[logos(skip r"[ \t\r\n\f]+")]
enum Token<'source> {
#[token("false", |_| false)]
#[token("true", |_| true)]
Bool(bool),
#[token("{")]
BraceOpen,
#[token("}")]
BraceClose,
#[token("[")]
BracketOpen,
#[token("]")]
BracketClose,
#[token(":")]
Colon,
#[token(",")]
Comma,
#[token("null")]
Null,
#[regex(r"-?(?:0|[1-9]\d*)(?:\.\d+)?(?:[eE][+-]?\d+)?", |lex| lex.slice().parse::<f64>().unwrap())]
Number(f64),
#[regex(r#""([^"\\\x00-\x1F]|\\(["\\bnfrt/]|u[a-fA-F0-9]{4}))*""#, |lex| lex.slice())]
String(&'source str),
}
/// Represent any valid JSON value.
#[allow(unused)]
#[derive(Debug)]
enum Value<'source> {
/// null.
Null,
/// true or false.
Bool(bool),
/// Any floating point number.
Number(f64),
/// Any quoted string.
String(&'source str),
/// An array of values
Array(Vec<Value<'source>>),
/// An dictionary mapping keys and values.
Object(HashMap<&'source str, Value<'source>>),
}
/// Parse a token stream into a JSON value.
fn parse_value<'source>(lexer: &mut Lexer<'source, Token<'source>>) -> Result<Value<'source>> {
if let Some(token) = lexer.next() {
match token {
Ok(Token::Bool(b)) => Ok(Value::Bool(b)),
Ok(Token::BraceOpen) => parse_object(lexer),
Ok(Token::BracketOpen) => parse_array(lexer),
Ok(Token::Null) => Ok(Value::Null),
Ok(Token::Number(n)) => Ok(Value::Number(n)),
Ok(Token::String(s)) => Ok(Value::String(s)),
_ => Err((
"unexpected token here (context: value)".to_owned(),
lexer.span(),
)),
}
} else {
Err(("empty values are not allowed".to_owned(), lexer.span()))
}
}
/// Parse a token stream into an array and return when
/// a valid terminator is found.
///
/// > NOTE: we assume '[' was consumed.
fn parse_array<'source>(lexer: &mut Lexer<'source, Token<'source>>) -> Result<Value<'source>> {
let mut array = Vec::new();
let span = lexer.span();
let mut awaits_comma = false;
let mut awaits_value = false;
while let Some(token) = lexer.next() {
match token {
Ok(Token::Bool(b)) if !awaits_comma => {
array.push(Value::Bool(b));
awaits_value = false;
}
Ok(Token::BraceOpen) if !awaits_comma => {
let object = parse_object(lexer)?;
array.push(object);
awaits_value = false;
}
Ok(Token::BracketOpen) if !awaits_comma => {
let sub_array = parse_array(lexer)?;
array.push(sub_array);
awaits_value = false;
}
Ok(Token::BracketClose) if !awaits_value => return Ok(Value::Array(array)),
Ok(Token::Comma) if awaits_comma => awaits_value = true,
Ok(Token::Null) if !awaits_comma => {
array.push(Value::Null);
awaits_value = false
}
Ok(Token::Number(n)) if !awaits_comma => {
array.push(Value::Number(n));
awaits_value = false;
}
Ok(Token::String(s)) if !awaits_comma => {
array.push(Value::String(s));
awaits_value = false;
}
_ => {
return Err((
"unexpected token here (context: array)".to_owned(),
lexer.span(),
))
}
}
awaits_comma = !awaits_value;
}
Err(("unmatched opening bracket defined here".to_owned(), span))
}
/// Parse a token stream into an object and return when
/// a valid terminator is found.
///
/// > NOTE: we assume '{' was consumed.
fn parse_object<'source>(lexer: &mut Lexer<'source, Token<'source>>) -> Result<Value<'source>> {
let mut map = HashMap::new();
let span = lexer.span();
let mut awaits_comma = false;
let mut awaits_key = false;
while let Some(token) = lexer.next() {
match token {
Ok(Token::BraceClose) if !awaits_key => return Ok(Value::Object(map)),
Ok(Token::Comma) if awaits_comma => awaits_key = true,
Ok(Token::String(key)) if !awaits_comma => {
match lexer.next() {
Some(Ok(Token::Colon)) => (),
_ => {
return Err((
"unexpected token here, expecting ':'".to_owned(),
lexer.span(),
))
}
}
let value = parse_value(lexer)?;
map.insert(key, value);
awaits_key = false;
}
_ => {
return Err((
"unexpected token here (context: object)".to_owned(),
lexer.span(),
))
}
}
awaits_comma = !awaits_key;
}
Err(("unmatched opening brace defined here".to_owned(), span))
}
fn main() {
let filename = env::args().nth(1).expect("Expected file argument");
let src = fs::read_to_string(&filename).expect("Failed to read file");
let mut lexer = Token::lexer(src.as_str());
match parse_value(&mut lexer) {
Ok(value) => println!("{:#?}", value),
Err((msg, span)) => {
use ariadne::{ColorGenerator, Label, Report, ReportKind, Source};
let mut colors = ColorGenerator::new();
let a = colors.next();
Report::build(ReportKind::Error, &filename, 12)
.with_message("Invalid JSON".to_string())
.with_label(
Label::new((&filename, span))
.with_message(msg)
.with_color(a),
)
.finish()
.eprint((&filename, Source::from(src)))
.unwrap();
}
}
}String interpolation
String interpolation is the ability to generate different strings at runtime, depending on the values of interpolated values. Many programming languages provide built-in features for string interpolation, like Python’s f-string. In this tutorial, we will see how we can build such a feature.
The input for our program will be written in a custom grammar that supports variable definitions. For simplicity, only string variables are supported. In addition to string literals, we also support string interpolation, which allows the incorporation of the values of previously defined variables into the current string.
Within a string interpolation expression, only variable names and new strings are allowed, meaning nested interpolations are possible.
Example input
name = 'Mark'
greeting = 'Hi ${name}!'
surname = 'Scott'
greeting2 = 'Hi ${name ' ' surname}!'
greeting3 = 'Hi ${name ' ${surname}!'}'
The variables in the example program should be assigned the following values:
name:Markgreeting:Hi Mark!surname:Scottgreeting2:Hi Mark Scott!greeting3:Hi Mark Scott!
Note that greeting3 uses nested interpolation.
Implementation
To parse our grammar, the lexer needs to identify tokens like identifiers (name, greeting, etc), assignment operators (=), and everything enclosed within single quotes (') as string literals. However, it must also process the string content itself to replace instances of interpolation (e.g., ${name}) with their corresponding values.
Handling this with a single lexer would be challenging, especially when the grammar allows recursive interpolation.
To address this, many lexer generators offer the ability to have separate lexers with their own set of patterns and tokens, allowing you to dynamically switch between them based on the context (see context-dependent lexing).
For our example we’ll use three lexers, one will handle the general syntax (variable definitions), another will handle the strings, and the third one will handle the interpolations:
type SymbolTable = HashMap<String, String>;
#[derive(Logos, Debug, PartialEq, Clone)]
#[logos(skip r"\s+")]
#[logos(extras = SymbolTable)]
enum VariableDefinitionContext {
#[regex(r"[[:alpha:]][[:alnum:]]*", variable_definition)]
Id((String /* variable name */, String /* value */)),
#[token("=")]
Equals,
#[token("'")]
Quote,
}
#[derive(Logos, Debug, PartialEq, Clone)]
#[logos(extras = SymbolTable)]
enum StringContext {
#[token("'")]
Quote,
#[regex("[^'$]+")]
Content,
#[token("${", evaluate_interpolation)]
InterpolationStart(String /* evaluated value of the interpolation */),
#[token("$")]
DollarSign,
}
#[derive(Logos, Debug, PartialEq, Clone)]
#[logos(skip r"\s+")]
#[logos(extras = SymbolTable)]
enum StringInterpolationContext {
#[regex(r"[[:alpha:]][[:alnum:]]*", get_variable_value)]
Id(String /* value for the given id */),
#[token("'")]
Quote,
#[token("}")]
InterpolationEnd,
}The idea for our parser will be the following:
-
VariableDefinitionContext:- This lexer handles the high-level grammar, in this case just the variable definitions.
- It identifies
Ids (variable names), assignment operators (=), and the starting quote (') of a string. - Upon encountering a quote (
'), the lexer transitions toStringContextto process the string content.
-
StringContext:- This lexer is dedicated to processing string literals.
- Regular text (excluding
$and') is matched as Content. - Any standalone
$is lexed separately but we’ll also consider it part of the content of the string literal. - When encountering the start of an interpolation (
${), it transitions toStringInterpolationContext. - A quote in this context (
') indicates the end of the string literal. The lexer transitions back toVariableDefinitionContextto resume parsing the rest of the program.
-
StringInterpolationContext:- This lexer handles the content of interpolation blocks (
${...}). - It recognizes
Ids and may encounter nested strings. Upon finding a quote ('), it transitions back toStringContextto start lexing the nested string. - The closing curly brace (
}) signals the end of the interpolation, allowing a return toStringContextto continue lexing the original string.
- This lexer handles the content of interpolation blocks (
We also want to store the values for each defined variable in a map, enabling us to replace their values during interpolation. To achieve this, we utilized Logos::Extras, adding a hash map (SymbolTable) to the lexers to keep track of variable definitions.
Additionally, we incorporated some callbacks to handle the heavy lifting. These callbacks will process the string content, manage context transitions, and perform interpolation evaluation. As a result, we’ll have the final key-value pairs stored in our main lexer, ready for use.
Below is an example of how the main function of our parser would look like:
fn test_variable_definition(
expected_id: &str,
expected_value: &str,
token: Option<Result<VariableDefinitionContext, ()>>,
) {
if let Some(Ok(VariableDefinitionContext::Id((id, value)))) = token {
assert_eq!(id, expected_id);
assert_eq!(value, expected_value);
} else {
panic!("Expected key: {} not found", expected_id);
}
}
fn main() {
let mut lex = VariableDefinitionContext::lexer(
"\
name = 'Mark'\n\
greeting = 'Hi ${name}!'\n\
surname = 'Scott'\n\
greeting2 = 'Hi ${name ' ' surname}!'\n\
greeting3 = 'Hi ${name ' ${surname}!'}!'\n\
",
);
test_variable_definition("name", "Mark", lex.next());
test_variable_definition("greeting", "Hi Mark!", lex.next());
test_variable_definition("surname", "Scott", lex.next());
test_variable_definition("greeting2", "Hi Mark Scott!", lex.next());
test_variable_definition("greeting3", "Hi Mark Scott!!", lex.next());
}Now, let’s define the callbacks that make this functionality possible. In Logos, context switching is handled using the morph method. This method takes ownership of the current Lexer and transforms it into a lexer for a new token type.
variable_definition
fn get_string_content(lex: &mut Lexer<StringContext>) -> String {
let mut s = String::new();
while let Some(Ok(token)) = lex.next() {
match token {
StringContext::Content => s.push_str(lex.slice()),
StringContext::DollarSign => s.push('$'),
StringContext::InterpolationStart(value) => s.push_str(&value),
StringContext::Quote => break,
}
}
s
}
fn variable_definition(lex: &mut Lexer<VariableDefinitionContext>) -> Option<(String, String)> {
let id = lex.slice().to_string();
if let Some(Ok(VariableDefinitionContext::Equals)) = lex.next() {
if let Some(Ok(VariableDefinitionContext::Quote)) = lex.next() {
let mut lex2 = lex.clone().morph::<StringContext>();
let value = get_string_content(&mut lex2);
*lex = lex2.morph();
lex.extras.insert(id.clone(), value.clone());
return Some((id, value));
}
}
None
}This callback is triggered when the VariableDefinitionContext lexer finds an Id token.
- We extract the variable name using
lex.slice().to_string(). - We expect an
Equals(=) followed by aQuote(') to signify the start of the string. - After that we clone the lexer and transition to
StringContextusing themorphmethod. Note that cloning is necessary becausemorphtakes ownership of the lexer but callbacks only get a mutable reference to it. - In the
StringContextwe call theget_string_contentfunction which parses the content of the string, concatenating all its parts intovalue. - Once the closing
Quote(') is found, we transition back toVariableDefinitionContext. - Lastly we insert the key-value pair into the symbol table and return the
(id, value)tuple which Logos will assign to theIdtoken.
evaluate_interpolation
The variable_definition callback expects the InterpolationStart token to have the evaluated value already assigned to it. This is where the evaluate_interpolation callback comes in:
fn evaluate_interpolation(lex: &mut Lexer<StringContext>) -> Option<String> {
let mut lex2 = lex.clone().morph::<StringInterpolationContext>();
let mut interpolation = String::new();
while let Some(result) = lex2.next() {
match result {
Ok(token) => match token {
StringInterpolationContext::Id(value) => interpolation.push_str(&value),
StringInterpolationContext::Quote => {
*lex = lex2.morph();
interpolation.push_str(&get_string_content(lex));
lex2 = lex.clone().morph();
}
StringInterpolationContext::InterpolationEnd => break,
},
Err(()) => panic!("Interpolation error"),
}
}
*lex = lex2.morph();
Some(interpolation)
}This callback is triggered when the StringContext lexer finds an InterpolationStart (${) token, signaling that an interpolation expression is beginning.
- We immediately transition to
StringInterpolationContextusingmorph. - If we find an
Idwe append its value to theinterpolationstring. - A
Quote(') in this context signals the beginning of a new string nested inside the interpolation. We switch back toStringContextand parse the nested string using theget_string_contentfunction defined previously.- Note that the recursion happens here, as finding a new
InterpolationStarttoken would create a new call toevaluate_interpolation.
- Note that the recursion happens here, as finding a new
- If we find
InterpolationEnd(}), the interpolation expression is complete. We switch back toStringContextand return theinterpolationstring so it gets assigned to theInterpolationStarttoken.
get_variable_value
Lastly we have the get_variable_value callback. This callback’s only job is to assign Id tokens in the StringInterpolationContext the value of the appropriate variable found in the symbol table.
fn get_variable_value(lex: &mut Lexer<StringInterpolationContext>) -> Option<String> {
if let Some(value) = lex.extras.get(lex.slice()) {
return Some(value.clone());
}
None
}Putting it all together
use std::collections::HashMap;
use logos::{Lexer, Logos};
type SymbolTable = HashMap<String, String>;
#[derive(Logos, Debug, PartialEq, Clone)]
#[logos(skip r"\s+")]
#[logos(extras = SymbolTable)]
enum VariableDefinitionContext {
#[regex(r"[[:alpha:]][[:alnum:]]*", variable_definition)]
Id((String /* variable name */, String /* value */)),
#[token("=")]
Equals,
#[token("'")]
Quote,
}
#[derive(Logos, Debug, PartialEq, Clone)]
#[logos(extras = SymbolTable)]
enum StringContext {
#[token("'")]
Quote,
#[regex("[^'$]+")]
Content,
#[token("${", evaluate_interpolation)]
InterpolationStart(String /* evaluated value of the interpolation */),
#[token("$")]
DollarSign,
}
#[derive(Logos, Debug, PartialEq, Clone)]
#[logos(skip r"\s+")]
#[logos(extras = SymbolTable)]
enum StringInterpolationContext {
#[regex(r"[[:alpha:]][[:alnum:]]*", get_variable_value)]
Id(String /* value for the given id */),
#[token("'")]
Quote,
#[token("}")]
InterpolationEnd,
}
fn get_string_content(lex: &mut Lexer<StringContext>) -> String {
let mut s = String::new();
while let Some(Ok(token)) = lex.next() {
match token {
StringContext::Content => s.push_str(lex.slice()),
StringContext::DollarSign => s.push('$'),
StringContext::InterpolationStart(value) => s.push_str(&value),
StringContext::Quote => break,
}
}
s
}
fn variable_definition(lex: &mut Lexer<VariableDefinitionContext>) -> Option<(String, String)> {
let id = lex.slice().to_string();
if let Some(Ok(VariableDefinitionContext::Equals)) = lex.next() {
if let Some(Ok(VariableDefinitionContext::Quote)) = lex.next() {
let mut lex2 = lex.clone().morph::<StringContext>();
let value = get_string_content(&mut lex2);
*lex = lex2.morph();
lex.extras.insert(id.clone(), value.clone());
return Some((id, value));
}
}
None
}
fn evaluate_interpolation(lex: &mut Lexer<StringContext>) -> Option<String> {
let mut lex2 = lex.clone().morph::<StringInterpolationContext>();
let mut interpolation = String::new();
while let Some(result) = lex2.next() {
match result {
Ok(token) => match token {
StringInterpolationContext::Id(value) => interpolation.push_str(&value),
StringInterpolationContext::Quote => {
*lex = lex2.morph();
interpolation.push_str(&get_string_content(lex));
lex2 = lex.clone().morph();
}
StringInterpolationContext::InterpolationEnd => break,
},
Err(()) => panic!("Interpolation error"),
}
}
*lex = lex2.morph();
Some(interpolation)
}
fn get_variable_value(lex: &mut Lexer<StringInterpolationContext>) -> Option<String> {
if let Some(value) = lex.extras.get(lex.slice()) {
return Some(value.clone());
}
None
}
fn test_variable_definition(
expected_id: &str,
expected_value: &str,
token: Option<Result<VariableDefinitionContext, ()>>,
) {
if let Some(Ok(VariableDefinitionContext::Id((id, value)))) = token {
assert_eq!(id, expected_id);
assert_eq!(value, expected_value);
} else {
panic!("Expected key: {} not found", expected_id);
}
}
fn main() {
let mut lex = VariableDefinitionContext::lexer(
"\
name = 'Mark'\n\
greeting = 'Hi ${name}!'\n\
surname = 'Scott'\n\
greeting2 = 'Hi ${name ' ' surname}!'\n\
greeting3 = 'Hi ${name ' ${surname}!'}!'\n\
",
);
test_variable_definition("name", "Mark", lex.next());
test_variable_definition("greeting", "Hi Mark!", lex.next());
test_variable_definition("surname", "Scott", lex.next());
test_variable_definition("greeting2", "Hi Mark Scott!", lex.next());
test_variable_definition("greeting3", "Hi Mark Scott!!", lex.next());
}As with the other examples you may run it by cloning the logos repository and executing this command:
cargo run --example string-interpolation
Contributing
If you are considering contributing to Logos, then this place is for you!
First, we really appreciate people that can help this project grow, and we would like to guide you through the standard contribution process.
There are many ways to help us, and here is a short list of some of them:
- fixing a BUG, by providing a patch (or suggesting in the comments how one could fix it);
- correcting some typos in the documentation, the book, or anywhere else;
- raising an issue about a problem (i.e., opening an issue on GitHub);
- proposing new features (either with an issue or a pull request on GitHub);
- or improving the documentation (either in the crate or in the book).
In any case, GitHub is the place-to-go for anything related to contributing.
Below, we provide a few help pages (or links) that can help you understand Logos’ internals and how you can submit a contribution.
- If you are new to GitHub or git, please consider reading those two guides:
- GitHub’s Hello World;
- and GitHub Pull Request in 100 Seconds (video).
- To setup and test your code locally, see the Setup page.
- To know a bit more how Logos works, check the Internals.
Setup
On this page, you will find all the information needed to run and test your own version of the Logos crate, locally.
We assume you have basic knowledge of git and GitHub. If that is not the case, please refer to the link mentioned in Contributing.
Prerequisites
You need to have both git and Rust installed on your computer, see installation procedures:
Once it’s done, clone the Logos repository on your computer:
git clone https://github.com/maciejhirsz/logos.git
If you have a fork of this repository, make sure to clone it instead.
Finally, launch a terminal (i.e., command-line) session and go to the
logos directory.
Checking the code compiles
A good way to see if you code can compile is to use the eponym command:
cargo check --workspace
Formatting and linting your code
Prior to suggesting changes in a pull request, it is important to both format your code:
cargo fmt
and check against Rust’s linter:
cargo clippy
Make sure to run those frequently, otherwise your pull request will probably fail to pass the automated tests.
Testing your code
Code that compiles isn’t necessarily correct, and testing it against known cases is good practice:
cargo test --workspace
You can also run benchmarks:
cargo bench --workspace --benches
Building the documentation
Logos’ documentation needs to be built with Rust’s nightly toolchain.
You can install the latest nightly channel with:
rustup install nightly
Then, use the following command to build the documentation with a similar configuration to the one used by docs.rs:
RUSTDOCFLAGS="--cfg docsrs" cargo +nightly doc \
--features debug \
-Zunstable-options \
-Zrustdoc-scrape-examples \
--no-deps \
--open \
Building the book
Logos’ book can be built with mdBook.
This tool can be installed with cargo:
cargo install mdbook
You also need to install mdbook-linkcheck2:
cargo install mdbook-linkcheck2
Then, from the root folder, you can build and serve the book with:
mdbook serve book --open
Any change in the ./book folder will automatically trigger a new build,
and the pages will be live-reloaded.
Internals
Logos’ core functionalities are split across five crates:
logosis the main crate, that you add to your project (inCargo.toml) to obtain theLogosderive macro. The public API is limited to this crate, and most users should only use this crate, not the others.logos-deriveis a very simple but necessary crate to exposelogos-codegen’s code as a derive macro.logos-codegencontains the most technical parts of Logos: the code that reads your token definitions, and generates optimized code to create blazingly fast lexers. You can read a blog post from the author of Logos to get a small insight of what thelogos-codegencrate does. In the future, we hope to provide more documents about how this crate works, so people are more likely to understand it and improve it with pull requests (see the Contributing section).logos-cliis a separate crate, that installs a binary of the same name, and allows to expand theLogosderive macro into code. It can be installed withcargo install logos-cli, and usage help can be obtained through thelogos-cli --helpcommand. This tool can be useful if your token definitions stay constant, and you want to reduce compilation time overhead caused by derive macros.logos-fuzzis an internal crate (i.e., unpublished) that uses afl.rs to find confusing panics before they reach the developer. To use this tool, see the Fuzzing guide
Fuzzing
Fuzzing is a technique to test a piece of software by injecting randomly generated inputs. This can be pretty useful to discover bugs, as pointed out in #407.
Logos’ fuzzing crate is powered by afl.rs that finds panics in Logos’ methods.
Usage
First, make sure you have cargo-afl installed,
see the rust-fuzz afl setup guide for installation information.
Next, change your current working directory to be the fuzz folder.
Building
Before fuzzing, you need to build the target with:
cargo afl build
Fuzzy testing
The recommended way the run tests is with:
cargo afl fuzz -i in -o out ../target/debug/logos-fuzz
Note that it may run for a (very) long time before encountering any bug.
Replaying a Crash
If you happen to find a bug that crashes the program, you can replay it with
cargo afl run logos-fuzz < out/default/crashes/crash_file
Reporting a Bug
If you encounter a crash and you feel the error message is not appropriate, please report it by opening an issue. Don’t forget to include your crash file so we can later reproduce it.